正規表現基礎
\s 空白文字を指定する
カテゴリー:文字クラス

余白を消すには?
さて、今回からは少し趣が変わります。
数字やアルファベットを捕まえるのではなく、文章に潜む空白を探り当てます。
正規表現で空白を表現するものは、\s です。
空白とは、スペース, \t (水平タブ), \n (改行), \r (復帰), \f (改ページ), \v (垂直タブ) の事です。
その為、文字クラスの [ \t\n\r\f\v] と同様になります。
但し \d の場合と等しく、フラグが必要になるプログラミング言語もあります。
\s を用いて、文章中の余白にマッチさせる事ができれば、それを置換して消すことができます。
上手く活用する事ができれば、実用性の高い処理になります。
それでは始めましょう。
この記事の難度は、基礎 Cクラスです。
(A: やさしい → E: 難しい)
事前知識として、pythonから正規表現を扱う方法が必要になります。 この他に、正規表現の文字クラスについての知識があるとよいでしょう。
| 難度 : | |
| 事前知識: | Pythonの基礎文法(reモジュールを含む)。この他に正規表現の文字クラス等。 |
| 学習効果: | \s を用いて、空白文字を 狭義/広義 にマッチさせ、余白を適切に消す事が出来るようになる。 |
Contens | 目次
| Chapter1 | Pythonで実行 |
Chapter1 Pythonで実行
空白について
最初に空白について説明します。
空白の中で、スペースや水平タブ、改行はイメージし易いと思います。
これに対して \r (復帰), \f (改ページ), \v (垂直タブ)は、あまり馴染みが無いかと思われます。
そこで、これらを実際に入力して、動きを確認してみます。
使用するPythonのバージョンは 3.7 です。
半角スペース
半角スペースは、キーボードのスペースキー(space key)の他、\u0020と入力します。
re_meta7_1.py
# bとCの間は半角スペース
st ="ab CD\u0020EF"
print(st)
実行結果
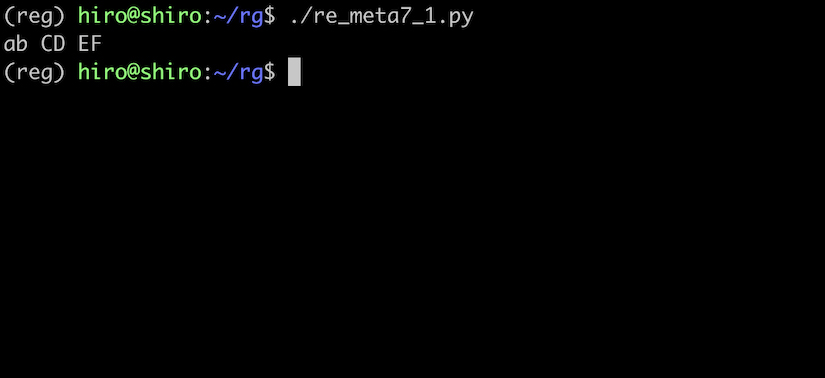
半角スペースが表示されました。
改行
\n か \u000A です。
re_meta7_2.py
st ="ab\nCD\u000AEF"
print(st)
実行結果
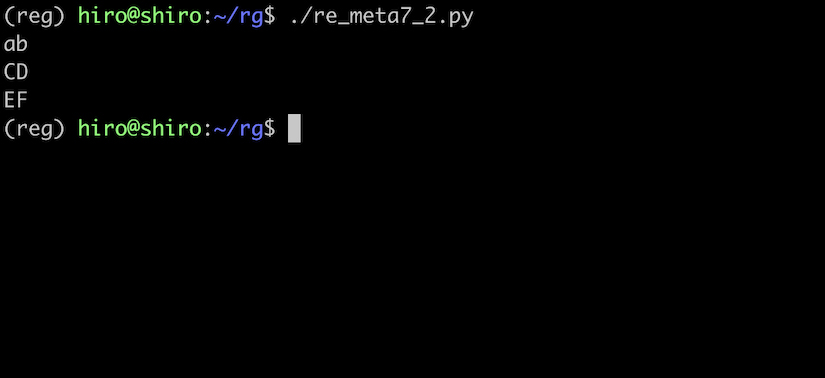
改行されています。
復帰
復帰は \r か \u000D と入力します。
これにより行頭に移動します。
re_meta7_3.py
st ="@@34\r1\n@@cd\u000Da"
print(st)
実行結果
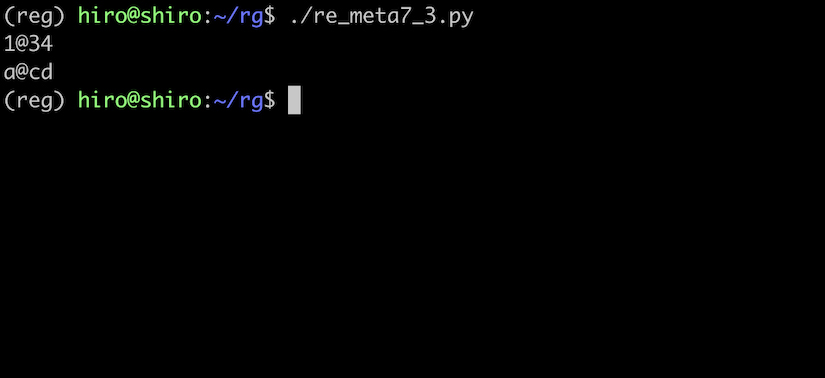
\r の後にある 1 が、行頭に入力されている事を確認できたと思います。
改ページ
\f か \u000c です。
re_meta7_4.py
st ="ab\fcd12\u000c34"
print(st)
実行結果
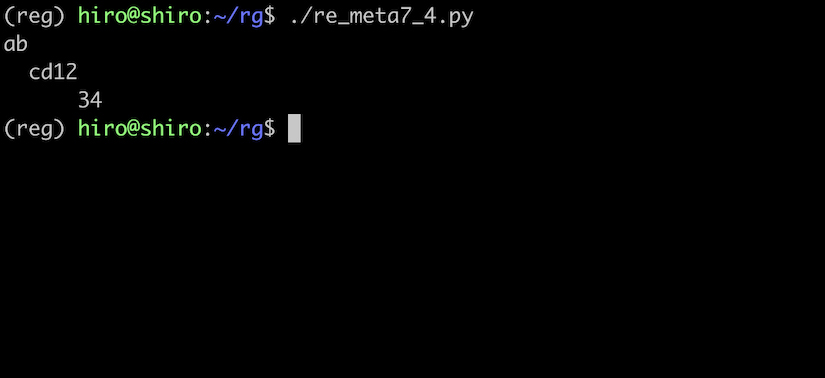
\f は、pythonからはこのように表示されました。
垂直タブ
垂直タブは \v か \u000b と入力します。
re_meta7_5.py
st ="ab\vcd12\u000b34"
print(st)
実行結果
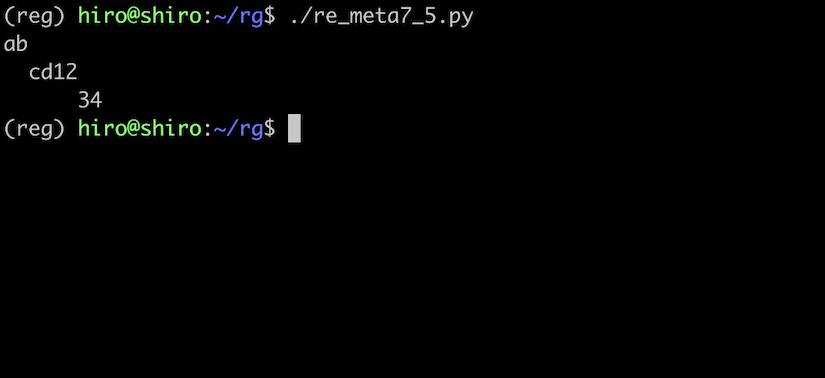
確認できたところで、\s をフラグ無しで実行してみましょう。
フラグなし
上で登場させた space,\t,\n,\r,\f,\v にマッチさせてみます。
re_meta7_6.py
import re
pattern = re.compile("\s")
# aとbの間は半角スペース
st ="a b\t\n\r\f\v"
result = pattern.findall(st)
print(result)
実行結果
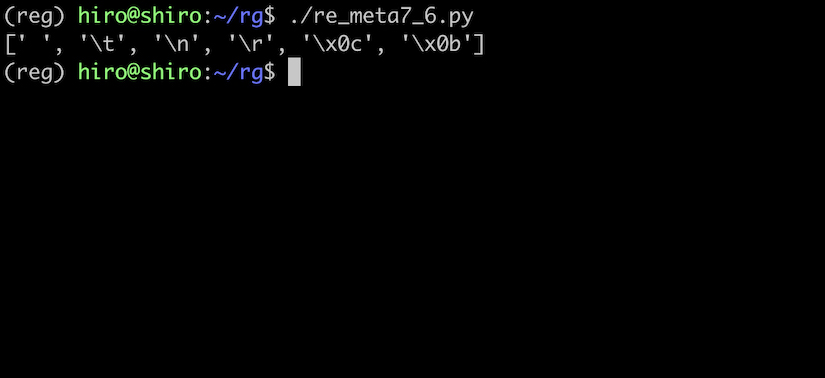
しっかりと一致しました。
そして、フラグを用いない場合は、空白の対象はより広義に解釈されます。
上記だけでなく、 全角の空白(\u3000)やノーブレークスペース(\u00A0)、Ogham Space Mark(\u1680)、Thin Space(\u2009)、、、などの空白も含まれます。
これらについても確認してみましょう。
re_meta7_7.py
import re
pattern = re.compile("\s")
# aとbの間は全角スペース
st ="a b\u3000c\u00A0d\u1680e\u2009f"
result = pattern.findall(st)
print(st)
print(result)
実行結果
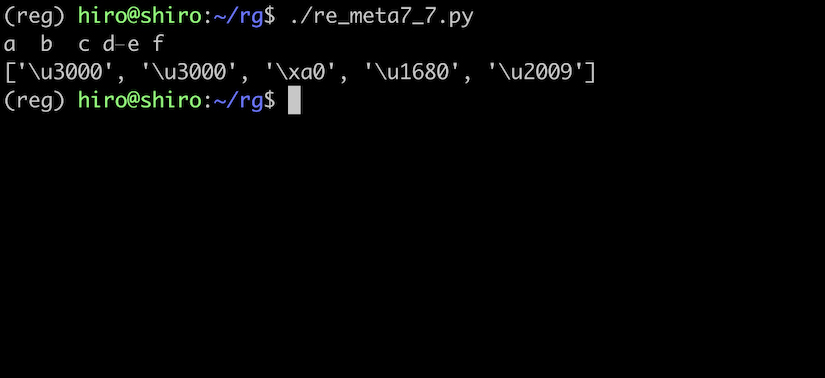
全角スペースなどにもマッチしています。
これは、パターンを [ \t\n\r\f\v] で構成した以下の場合と異なります。
re_meta7_8.py
import re
pattern = re.compile("[ \t\n\r\f\v]")
# aとbの間は全角スペース
st ="a b\u3000c\u00A0d\u1680e\u2009f"
result = pattern.findall(st)
print(result)
実行結果
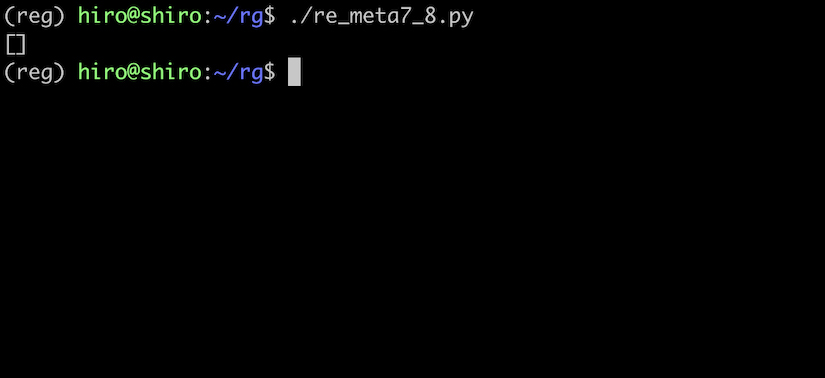
全角スペースなどには一致していません。
この結果と足並みを揃えるには、やはりフラグを用います。
ASCIIフラグ
ASCIIフラグを使うと、全角スペースなどを弾きます。
re_meta7_9.py
import re
pattern = re.compile("\s",flags=re.ASCII)
# a と b の間は全角スペース, f と h の間は半角スペース
st ="a b\u3000c\u00A0d\u1680e\u2009f h\t\n\r\f\v"
result = pattern.findall(st)
print(result)
実行結果
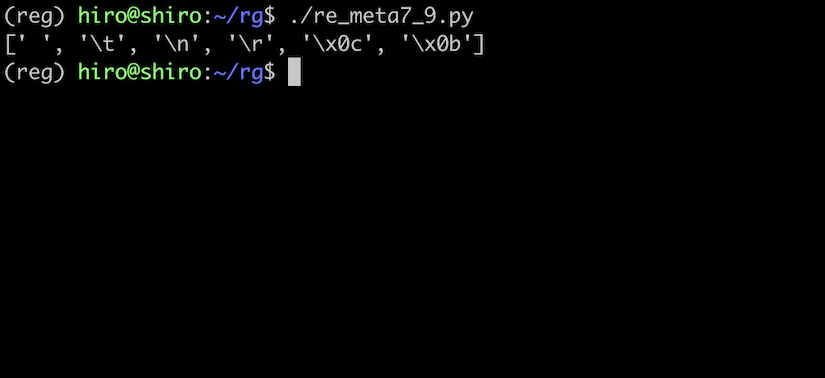
[ \t\n\r\f\v] と同じく、全角スペースなどにはマッチしていません。
インラインフラグ
インラインフラグでも同様の結果になります。
文字列パターンの先頭に (?a) を記述します。
re_meta7_10.py
import re
pattern = re.compile("(?a)\s")
# a と b の間は全角スペース, f と h の間は半角スペース
st ="a b\u3000c\u00A0d\u1680e\u2009f h\t\n\r\f\v"
result = pattern.findall(st)
print(result)
実行結果
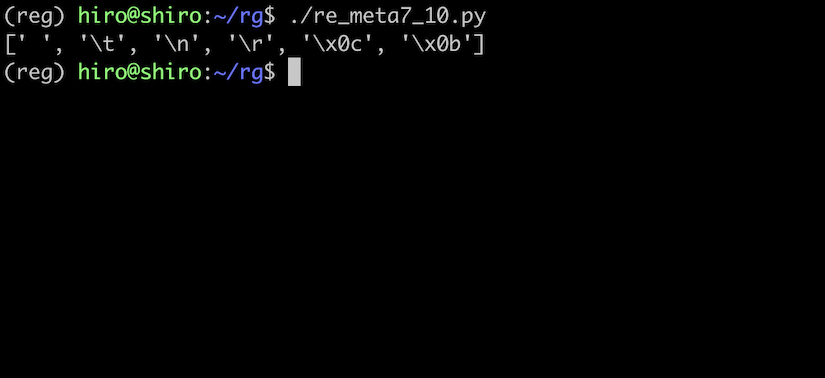
インラインフラグでも、meta7_9.pyと等しい結果になりました。
では最後に、このような空白文字を取り除く処理を行います。
余白を消す
余白を消すには、正規表現において文字列を置換するメゾットである sub() を使います。
(sub() については【正規表現による置換と分割】のページで詳しく説明しています。)
ASCIIフラグがある状態で実行してみます。
re_meta7_11.py
import re
pattern = re.compile("\s",flags=re.ASCII)
# a と b の間は全角スペース, f と 1 の間は半角スペース
st ="a b\u3000c\u00A0d\u1680e\u2009f 1\t2\n3\r4\f5\v6"
repl = ""
result = pattern.sub(repl,st)
print(result)
実行結果
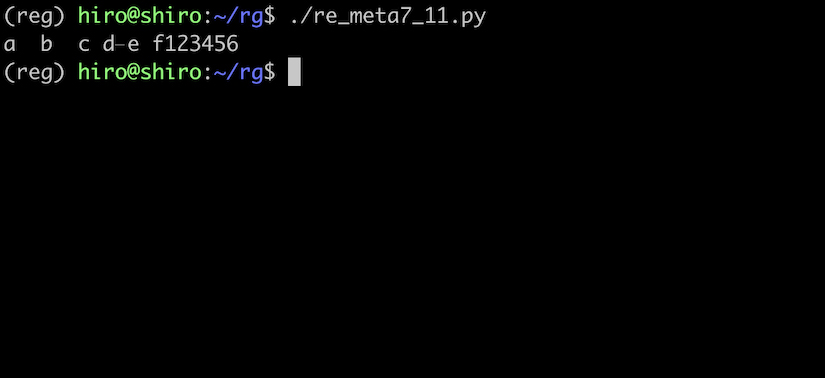
やはりフラグがあると、全角スペースなどは取り除かれません。
フラグを外して、空白を広義に解釈してこれを消去します。
re_meta7_12.py
import re
pattern = re.compile("\s")
# a と b の間は全角スペース, f と 1 の間は半角スペース
st ="a b\u3000c\u00A0d\u1680e\u2009f 1\t2\n3\r4\f5\v6"
repl = ""
result = pattern.sub(repl,st)
print(result)
実行結果
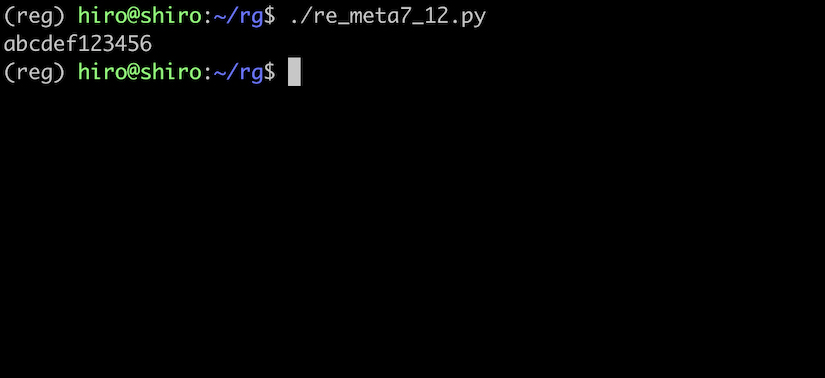
全角スペースなども消す事ができました。
\s についての解説はここまでです。
\s は、フラグの有無によって、広くも狭くも空白を解釈できます。
この性質を上手に利用して、適切に余白を消す事を習得できました。
次回は \S についてです。
関連記事

[ ] 文字集合を指定する
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法(reモジュールを含む) |
| 学習効果: | 文字クラスを細部まで理解できる。 |

\d 数字を指定する
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法(reモジュールを含む) |
| 学習効果: | \d を用いて、数字を 狭義/広義 にマッチさせる事が出来るようになる。 |

\D 数字以外を指定する
| 正規表現: | 文字クラス |
| 難度 : | 入門〜基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \D を用いて、数字以外を 狭義/広義 にマッチさせる事が出来るようになる。 |

\w 単語構成文字
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \w を用いて、単語構成文字を 狭義/広義 にマッチさせる事が出来るようになる。 |

\W 単語構成文字以外
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \W を用いて、単語構成文字以外を 狭義/広義 にマッチさせる事が出来るようになる。 |

\s 空白文字を指定する
| 正規表現: | 文字クラス |
| 難度 : | 基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \s を用いて、空白文字を 狭義/広義 にマッチさせ、余白を適切に消す事が出来るようになる。 |

\S 空白以外を指定する
| 正規表現: | 文字クラス |
| 難度 : | 入門〜基礎 |
| 事前知識: | Pythonの基礎文法。正規表現の文字クラス等。 |
| 学習効果: | \S を用いて、空白文字以外を 狭義/広義 にマッチさせ、余白以外の文字を取得できる。 |

. 改行以外の任意の1文字
| 正規表現: | 文字クラス |
| 難度 : | 入門〜基礎 |
| 事前知識: | Pythonの基礎文法。エスケープ文字である \ (バックスラッシュ)等。 |
| 学習効果: | . を用いて、幅広いマッチが出来るようになる。 |

正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |