正規表現入門
パターンを探すメゾットを知る
カテゴリー:Pythonから使う

よく似てる ?
前回に引き続きpythonで正規表現を扱う方法を解説します。
さて今回は、パターンを探すメゾットに焦点を当てます。
対象とする文字列からパターンを探すのに、前回は search() を用いました。
しかしパターンを検索できるメゾットはこれ以外にもいくつかあり、中には似通ったものさえあります。
これらを適切に扱うには、使用目的に照らし合わせるのがよいでしょう。
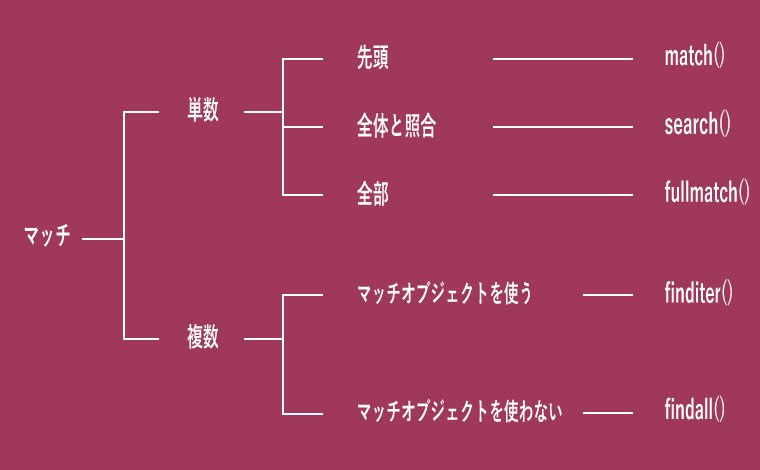
その切り分けとしては、対象文字列の中でパターンが複数回出現するのか、或いは単数なのかを先ず考えます。
次に単数でのマッチならば、文字列中の何処にマッチさせたいのかで区切ります。
複数回出現する場合は、マッチオブジェクト(第二章で細述します。)を利用したいのかどうかで決めます。
パターンを探すメゾットの使用目的による使い分け
詳述は第一章より始めます。
これらを把握すれば、パターンを探すメゾットの適切な使い分けができるようなります。
この記事の難度は、入門〜基礎 Bクラスです。
(A: やさしい → E: 難しい)
pythonの事前知識として入門〜基礎程度があれば充分です。
| 難度 : | |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | パターンを探すメゾットを、使用目的により使い分けることが出来るようになる |
Contens | 目次
| Chapter1 | 単数マッチ |
| Chapter2 | マッチオブジェクト |
| Chapter3 | 複数回のマッチ |
Chapter1 単数マッチ
何処にマッチさせたいの?
第一章では、対象文字列中にパターンが単数で現れている場合について考えます。
このような時は、match() や search() 或いは fullmatch() などを用いるとよいでしょう。
match() は対象とする文字列の先頭を、search() は文字列全体から探したい箇所を、fullmatch() は文字列全部を対象にしてマッチ判定を行います。
match()から順に説明します。
match()
match() は、serach() によく似ていますが、文字列の先頭のみをマッチ判定の対象にします。
先頭がマッチするなら、それに対応するマッチオブジェクトを返しますが、先頭以外でマッチが発生してもマッチオブジェクトは返却されません。(None を返します)
例として以下のようなコードをみてみましょう。
(パターンが "a" で対象とする文字列は "same" です。)
re_python2_1.py
import re
pattern = re.compile(r"a")
result = pattern.match("same")
print(result)
実行結果
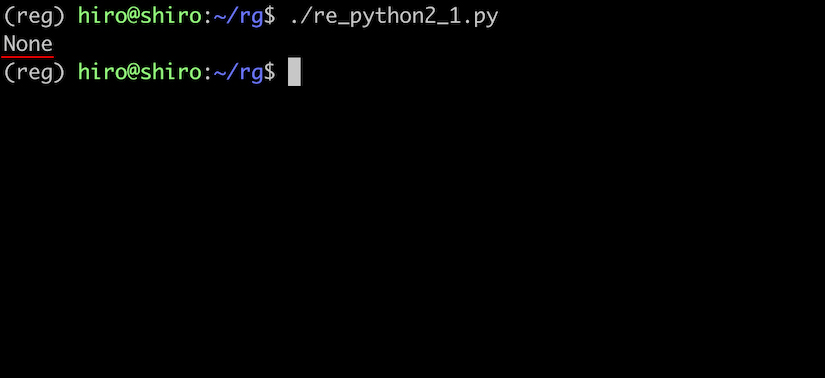
結果はNoneです。
先頭が "s" で "a" ではないからです。
これをマッチさせるには、パターンを r"s" に指定します。
re_python2_2.py
import re
pattern = re.compile(r"s")
result = pattern.match("same")
print(result)
実行結果
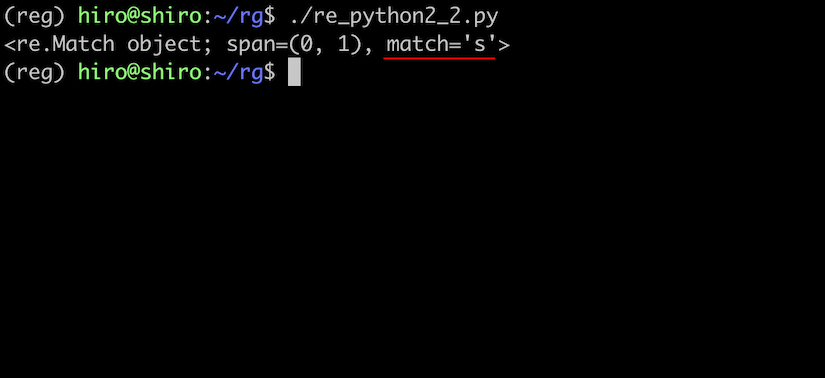
先頭のsにマッチしました。
このように、match()は文字列の先頭部分しかその対象にしないので、文字列全体と照らし合わせたい場合には search() を使います。
search()
search()を使うと、対象とする文字列全体からパターンを探すので、先程はマッチしなかった以下の場合にもマッチするようになります。
re_python2_3.py
import re
pattern = re.compile(r"a")
result = pattern.search("same")
print(result)
実行結果
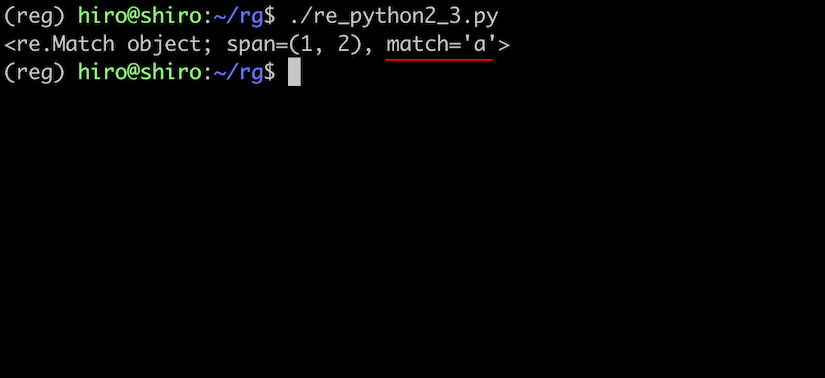
マッチしました。
fullmatch()
fullmatch() は、対象とする文字列全てがパターンに適合するかを調べます。
search() ではマッチした以下のような場合でも、fullmatch() では不一致になります。
"same" という文字列の中で "a" の部分しか一致していない為です。
re_python2_4.py
import re
pattern = re.compile(r"a")
result = pattern.fullmatch("same")
print(result)
実行結果
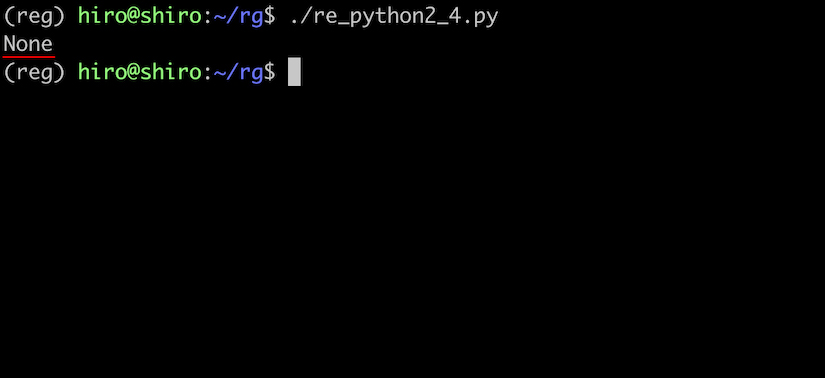
マッチさせるには以下のように修正します。
re_python2_5.py
import re
pattern = re.compile(r"same")
result = pattern.fullmatch("same")
print(result)
実行結果
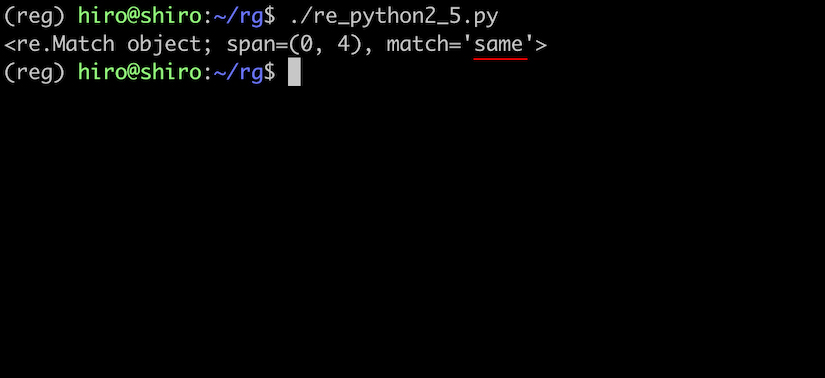
一致しました。
Chapter2 マッチオブジェクト
一致した文字列を取り出すには?
この章では趣を変えてマッチオブジェクトについて説明します。
マッチオブジェクトを用いるとパターンがマッチした際、一致した文字列を抽出できます。
第1章で紹介した match(), search(), fullmatch() はマッチすると、それに対応するマッチオブジェクトを返却します。
マッチオブジェクトの group() により正規表現にマッチする文字列を取得できます。
re_python2_6.py
import re
pattern = re.compile(r"a")
result = pattern.search("same")
if result:
print(result.group())
実行結果
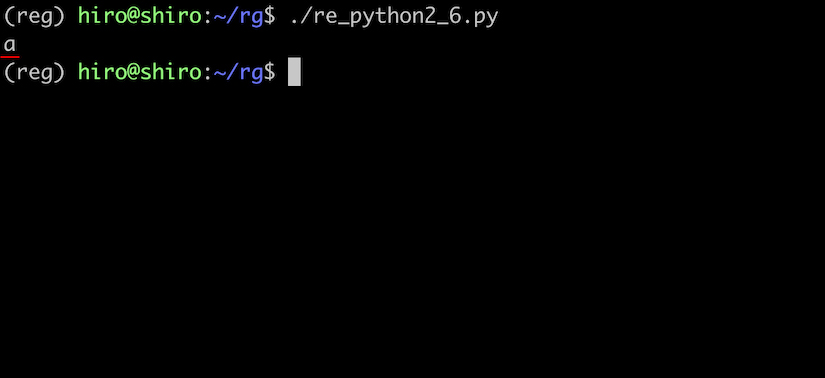
マッチした文字を取り出せました。
この他にも、パターンがマッチした具体的な位置を以下のメゾットにより調べられます。
開始位置を探るには、start() を、
終了位置は end() で、
一致した範囲については、span() をそれぞれ適用します。
re_python2_7.py
import re
pattern = re.compile(r"a")
result = pattern.search("same")
if result:
print("start:",result.start())
print("end:",result.end())
print("span:",result.span())
実行結果
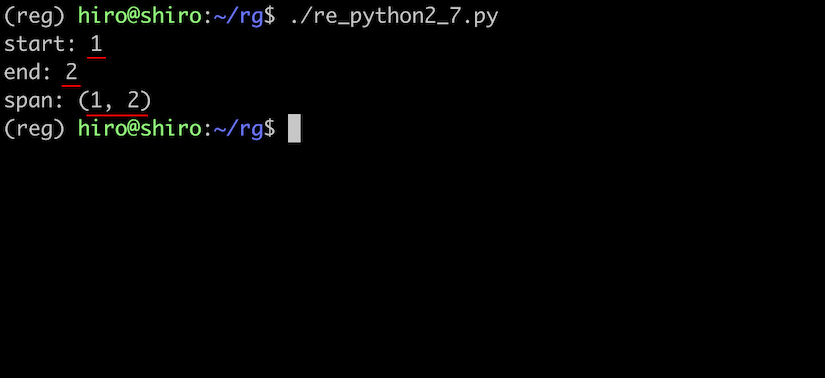
位置についての詳細を表示できました。
それから、マッチの対象となった文字列であったり、パターンを確認するには次のようにします。
re_python2_8.py
import re
pattern = re.compile(r"a")
result = pattern.search("same")
if result:
#パターンを確認
print(result.re)
#対象文字列の表示
print(result.string)
実行結果
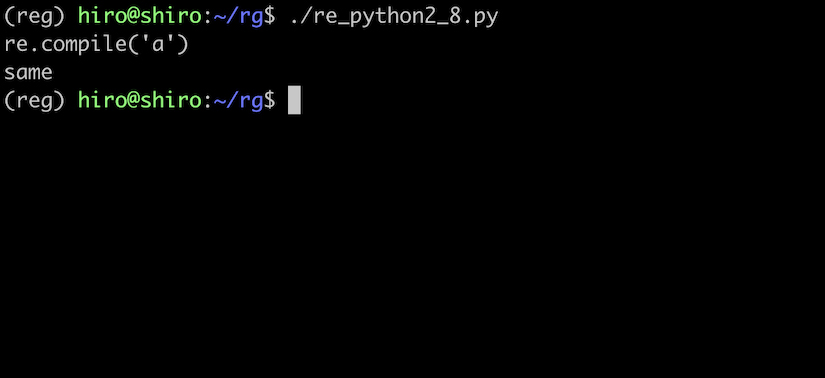
さらに group() について...
group() は、パターンがグループ化された場合にその効能を発揮します。
グループ化とは、() を使ってパターンの一部を一纏まりにすることです。(グループ化の詳述は【基礎3 グループ・選択】で行います)
例えば、文字列のパターンとして "suns" があったとします。
これを、() を用いて適当な箇所でグループ化すると 、"(sun)" と "(s)" のように分けられます。
パターンがマッチした場合、そのグループ化された部分を抽出するには、group()の引数にグループ番号を指定します。
group(1)なら (sun) の部分、group(2) で (s) の部分になります。(group(0) は全体)
実際に試してみましょう。
対象となる文字列が "sunshine" で、パターンである r"suns" を (sun) と (s) でグループ化します。
re_python2_9.py
import re
pattern = re.compile(r"(sun)(s)")
result = pattern.search("sunshine")
if result:
print("group(0):",result.group(0))
print("group(1):",result.group(1))
print("group(2):",result.group(2))
実行結果
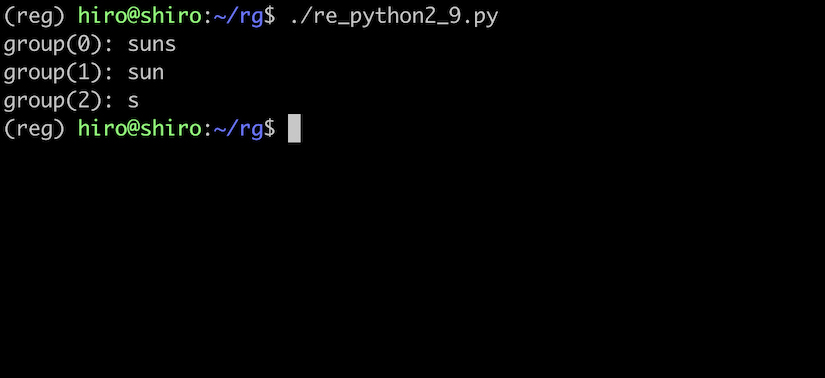
引数のグループ番号に対応していることが確認できました。
group()の引数にグループ番号を複数個指定すると、それに応じたタプルになります。
またはgroups()でも同様です。
re_python2_10.py
import re
pattern = re.compile(r"(sun)(s)")
result = pattern.search("sunshine")
if result:
print(result.group(1,2),type(result.group(1,2)))
print(result.groups())
実行結果
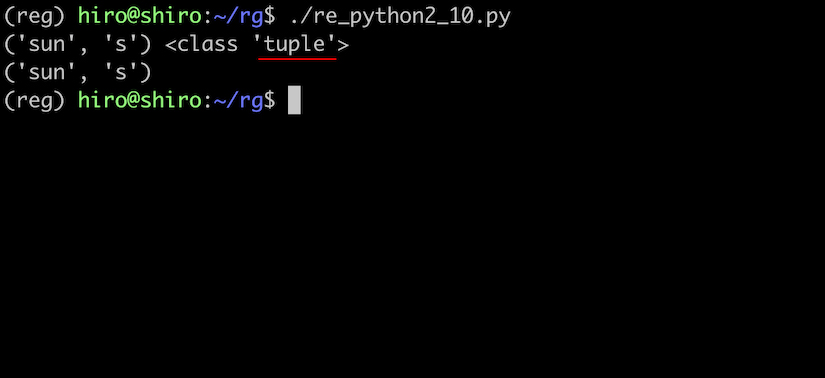
グループ数が多くあり、抽出にループを使いたい場合は lastindex を利用します。
lastindex は最後にマッチしたグループ番号を取得できるので、これによりループを構成できます。
re_python2_11.py
import re
pattern = re.compile(r"(si)(c)(o)(chemi)(c)")
result = pattern.search("physicochemical")
if result:
for i in range(result.lastindex + 1):
print('group{num};'.format(num = i),result.group(i))
実行結果
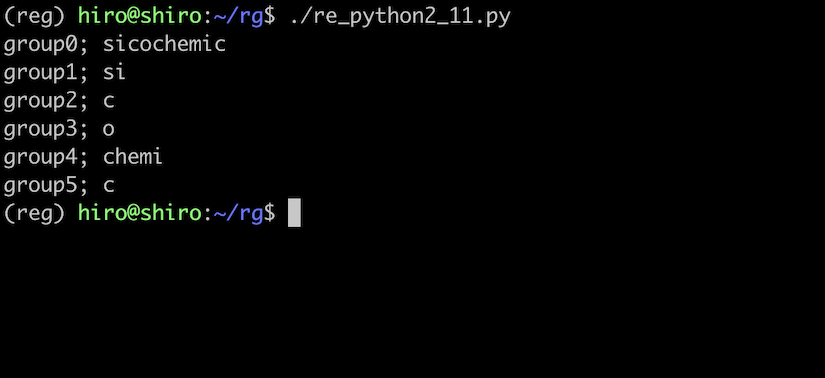
ループによりまとめて処理できました。
Chapter3 複数回のマッチ
複数マッチに対応する
この章では、複数マッチを処理できるメゾットについて解説します。
対象となった文字列の中でパターンが複数回出現しても、search() では最初のマッチ箇所しか対応しません。
以下の例では、パターン "a" が3回マッチしていますが、最初のみ取り扱われています。
re_python2_12.py
import re
pattern = re.compile(r"a")
result = pattern.search("sabbatical")
if result:
print("span:",result.span())
実行結果
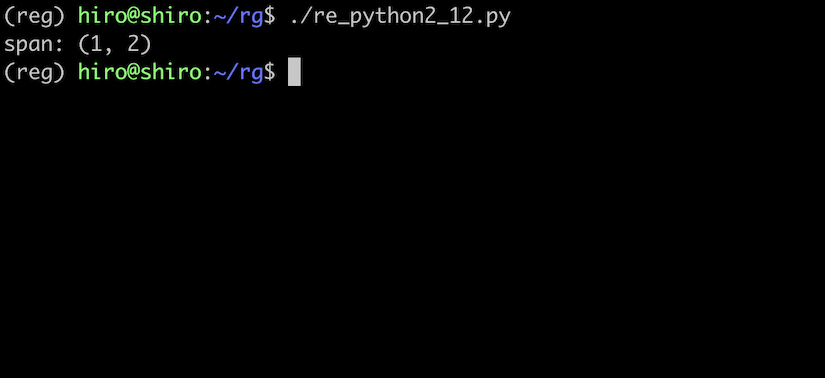
マッチした項目全てに対処するには、findall() や finditer() を使います。
findall() はマッチした部分をリストで返します。
re_python2_13.py
import re
pattern = re.compile(r"a")
result = pattern.findall("sabbatical")
if result:
print(result)
print(type(result))
実行結果
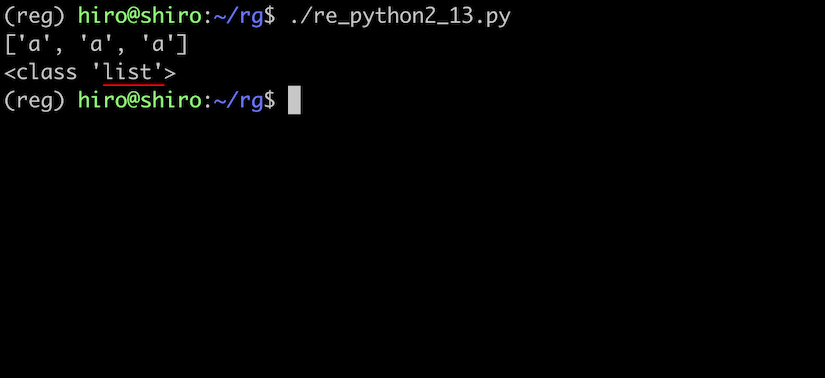
3回分のマッチに対応しています。
しかし、これでは何処でマッチしたのか分かりません。
マッチした位置を調べたくても、返却値がマッチオブジェクトではないので span() 等を活用できません。
そこで一致した場所まで確認したい場合には、マッチオブジェクトにアクセスできるfinditer() に任せます。
なお、戻り値はイテレータです。
re_python2_14.py
import re
pattern = re.compile(r"a")
result_iter = pattern.finditer("sabbatical")
print("type",type(result_iter))
for result in result_iter:
print(result.group())
print(result.span())
print("type:",type(result))
実行結果
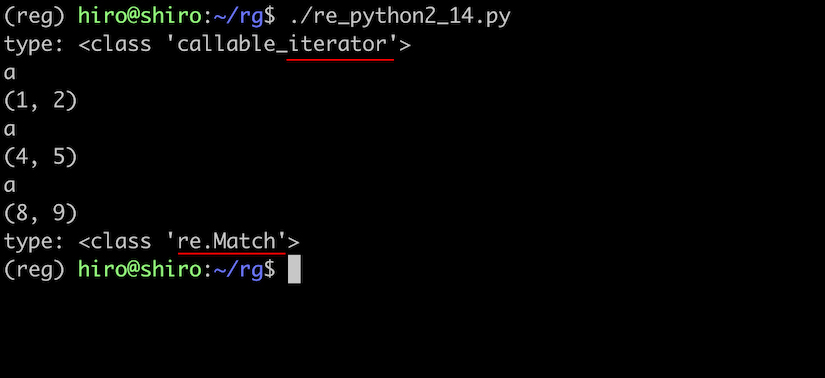
複数回のマッチを、その位置まで含めて抽出できました。
これをもって、パターンを探すメゾットの基礎的な話は終わりにします。
それぞれの性質を理解したので、使用目的を照合して、メゾットを適切に使い分けることが出来るようになりました。
関連記事

正規表現をPythonから使う 3
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | 正規表現による、マッチした箇所の置換や分割操作の習得。"チョコレート"を"チョコ"に変える。 |
正規表現をPythonから使うには ?
| 正規表現: | Pythonから使う |
| 難度 : | 入門 |
| 事前知識: | Pythonの基礎文法 |
| 学習効果: | pythonから正規表現を使う一連の流れを掴む |

正規表現とは?
| 正規表現: | 概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | 正規表現の概要を知る |

ハロー ! メタキャラクタ
| 正規表現: | メタキャラクタの概要 |
| 難度 : | 入門 |
| 事前知識: | 不要 |
| 学習効果: | メタキャラクタの概要を掴む |